
Part 1:Uncovering Ebola Protein Function Through Computational Science
One of the best ways a DIY Scientist can contribute is by performing Bioinformatics or Computational Biology work. If you have access to a computer then there is no cost. Though computational power can be limiting even with a personal computer all that it takes is a little patience to accomplish something cool and useful. I once let my computer run for close to a year to perform a number of molecular dynamics simulations! Proteins are amazing little nanomachines that control cells and life. This article is a tutorial focusing on understanding how proteins function, from sequence analysis to protein structure simulation. Because of the significant depth of these Scientific topics I will not write much about the underlying molecular biology but will attempt to point readers to the correct sources. Basic knowledge of Proteins and DNA will be helpful but should not be required to follow along and though we will focus on a single protein these protocols should be directly applicable to other systems.
What you need:
- A computer
- Visual Molecular Dynamics
(http://www.ks.uiuc.edu/Development/Download/download.cgi?PackageName=VMD)
Using NCBI For Data Gathering and Hypothesis Generation
Whenever I am beginning any Biotechnology project I start at the NCBI (http://www.ncbi.nlm.nih.gov/). Most any sequence information or Scientific paper can be found through this website. To begin this tutorial we first need a project. Having direction and perhaps a hypothesis are very important. A good place to start is by reading Scientific literature. Maybe you are interested in plants and how they generate secondary metabolites for protection or bacteria and how they evolve antibiotic resistance. Myself I am interested in viruses because they are little scary machines! I am actually not a virologist so I will just go with the Ebola virus because it seems really scary. So let’s start at PubMed. At the NCBI webpage change the drop-down menu that reads “All Databases” to “PubMed” then let’s search for “ebola virus protein function”.
When we scroll down through the list we see that there are a few well known viral proteins in Ebola that appear to function in it’s efficacy(it’s ability to kill things), those being VP24, VP35 and VP40. There are definitely more but this seems like a good place to start. One of the papers has a really cool title “The ebolavirus VP24 interferon antagonist: know your enemy.” that is actually how I choose which papers to read, by cool titles (joking, kind of) (http://www.ncbi.nlm.nih.gov/pubmed/23076242). This article is great, it even goes into detail about what specific amino acids could be important for function. We can use it later to help achieve a better understanding of the protein and come up with some basic hypotheses. Proteins are a chain of amino acids and these amino acids “fold” to create very complex interaction networks that gives proteins function (http://en.wikipedia.org/wiki/Protein_structure). Every Biological Scientist should have their amino acids memorized, you should know the one and three letter codes, the chemical structure, the charge and at least be able to give a good guess at the pKa if it has one that is reasonable, (http://en.wikipedia.org/wiki/Amino_acid). This isn’t just a silly party trick(but you can use it to impress your friends). It seriously will hinder your ability to analyze any protein data if you cannot look at a sequence and understand the importance of say an Arginine as opposed to Alanine or know that the one letter code for Arginine is ‘R’ and Alanine is ‘A’ (Arginine is consistently found in parts of the protein that bind other macromolecules especially DNA, while Alanine, well it is just a small hydrophobe, kind of boring, sorry Alanine). Make note cards and memorize them on your way to work in the morning for a week or two. You will thank yourself later.
Understanding Protein Structure Through Multi-Sequence Alignments
Ok so now we have a target, VP24, we want to understand what parts of it are important and how those parts contribute to making it an interferon agonist, suppressing immune responses to allow the virus to infect and kill people. Let’s go back to the NCBI page and search “Proteins” for VP24. A simple way to identify interesting parts of proteins is through homology, or ancestry. As an organism gives rise to another species pieces of DNA that do not contribute to the fitness of the organism would be able to accumulate mutations because those mutations don’t kill the organism. The mutations that kill the organism will not be able to propagate obviously! The actual process is much more complicated but this is the basis of evolution and can be used to determine how “important” a specific portion of DNA or protein are to it’s overall functionality. Let’s compare these viral protein sequences. On the right side of the search results there is a region titled “Taxonomic Groups” click on “Mononegavirales”. We want to narrow down our sequence search space to sequences that most likely have a similar function as VP24 in Ebola. Now we need to pick some sequences to compare. Mostly, I am just choosing sequences from different species to increase our sequence space as most sequences from a single species will likely be very similar or identical and will thus provide little information about mutation accumulating regions. I checked boxes: 1, 2, 21, 22, 28, 50, 54, 55(these numbers will probably change over time). Then click on “Send to:” at the top or bottom of the page, then “File” and then choose the Format “FASTA” and click create file and download it or just use a version that I saved that you can just download it here: https://docs.google.com/document/d/1JiC1Ek8Dh3_GlRKbqsH3wjJFQJeyZ7M1aQ2EZ2ue1CI/edit?usp=sharing)
Now we are going to compare all these sequences using some sweet algorithms. ClustalOMEEEGAAAA (I like to say it in a sweet Robot.Giant Being with echoing voice type voice) (https://www.ebi.ac.uk/Tools/msa/clustalo/). We can just upload our sequence file and click “Submit”.
It should only take 10 or 30 seconds before the alignment pops up. This is the amino acid sequence of each VP24 protein from the different species I chose. Instead of using the protein name or species they use all the accession and identification numbers. The protein that we are interested in from the paper, the Sudan ebolavirus is gi|498541200|gb|AGL50930.1|
This sequence alignment is displayed using the single letter amino acid codes. When all of the proteins that are compared have the same amino acid in a position in the sequence there is a * underneath the single letter code. For instance, the two first amino acids M(Methionine which is the first amino acid in almost every single protein) and A(Alanine, remember it?), are found in every copy of this protein we are comparing. Are they important? Well since M is the “Start” amino acid this conservation between species is insignificant. The A may be significant but let us look deeper. When there is two dots : underneath a single letter code it means that all the amino acids in this position have very very similar characteristics, the fifth amino acid is both S(Serine) and T(Threonine) among the proteins, this position has two dots, “:”, because S and T are very similar in structure and character, i.e. both have an OH on their side-chain. When there is a single dot “.”, this means that there are some amino acids in this position that are similar or identical but also some that are more dissimilar. In position three there is a single dot underneath K, R and E. Both K(Lysine) and R(Arginine) have the positive dipoled NHx on their side-chains (a dipole is just a local electrostatic field. Opposite charges attract and similar charges repel http://en.wikipedia.org/wiki/Dipole) while E(Glutamic Acid or Glutamate) has a negative dipoled OH. Since most of the amino acids in this position are similar and some are dissimilar it has one dot. If the amino acids in a position are very dissimilar then there is no mark underneath the position in the sequence.
Ok so remember important regions will be conserved and so should have a “*” and less important regions should be more mutated. What we want to look for is clusters of “*”. In the second row we see a sequence TRNLFPHLFKN(residues 72-82) and in the fourth row we see IIITRTVMGFLVE(residues 188-200). If we look at residues from the early paper that should be important 96-98 and 106-121 we see that 96-98(VIL) are conserved as hydrophobic very well and probably to about residue 115 are very conserved but 116-121 do not appear very conserved. Not all important residues in a protein are conserved as new residues are how proteins gain new function but this analysis is still useful to find potentially interesting regions.
Using RCSB and Viewing Protein Structure Models
Let’s attempt to find the model structure of the protein that they talk about in the paper. Most structures can be found at the Research Collaboratory for Structural Bioinformatics (RCSB) and these protein structure files are called Protein Data Bank (PDB) files. These files contain the atoms and their arrangement in three-dimensional space. Ok so at the RCSB let’s search for “VP24 Sudan” and see if anything shows up. We have some hits! Let’s check out PDB ID: 3VNE (http://www.rcsb.org/pdb/explore/explore.do?structureId=3VNE). This structure was solved using X-ray Crystallography(http://en.wikipedia.org/wiki/X-ray_crystallography), which means they shine X-rays at proteins formed into crystals and are able to reconstruct the structure based on how these X-rays diffract off the electrons in the crystal. If we click on the Sequence tab at the top we open up a webpage that shows the amino acid sequence of the protein and the secondary structure overlaid on top of it.
Proteins have three basic types of secondary structure. The alpha helix(helix)(http://en.wikipedia.org/wiki/Alpha_helix), the beta strand ((arrow shaped) a number of bet-strands next to each other make up a beta-sheet)(http://en.wikipedia.org/wiki/Beta_strand) and the loop(curve). This secondary structure is determined by the amino acid sequence and it helps determine the tertiary structure, what the PDB model shows.
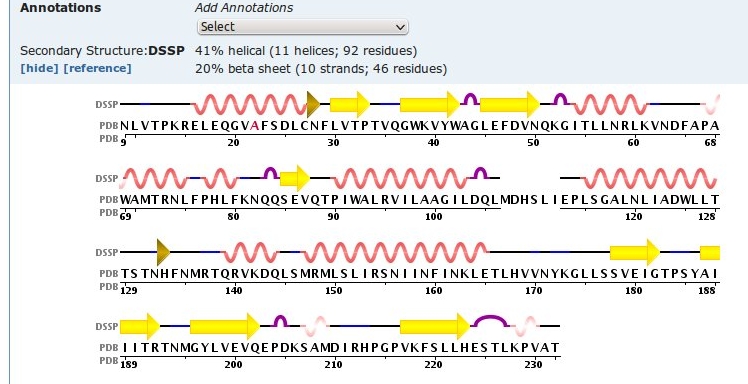
Let’s download this structure file by clicking on “Download Files” on the right hand side and click on “PDB File (text)” it should ask you to download 3VNE.pdb. Now in order to view it on our computer so we can look at it in a more detailed fashion we need to use a molecular modeling program. Visual Molecular Dynamics(VMD) is a free program developed by the University of Illinois (http://www.ks.uiuc.edu/Development/Download/download.cgi?PackageName=VMD). If you have not already install the program and then let’s view our structure.
Using VMD
Open up VMD and goto “File” and then “New Molecule” and choose 3VNE.pdb.
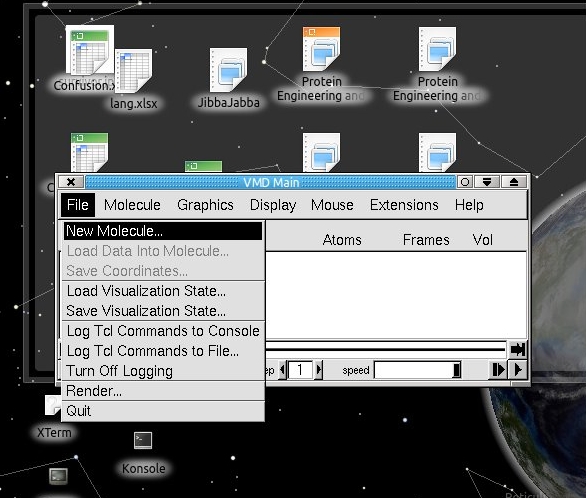
Once the protein model is open let’s change the representation method to make it easier to look at. Goto “Graphics” and then “Representations”. Change “Drawing Method” to “New Cartoon”. Now it should look like the secondary structure elements we saw before. The arrow looking things are the beta-strands and the helical looking things are alpha helices.
Now when viewing the molecule you have three basic ways to manipulate the molecule by clicking on the image and pressing the “R” key you can Rotate the molecule, by pressing the “T” key you can Translate the molecule and by pressing the “S” key you can Scale the molecule. Ok let’s find the amino acids in the protein structure that the paper pointed out as important for function, residues 96-98 and 106-121. To visualize these amino acid we need to click on “Create Rep” in the Graphical Representations window. We should have a new entry. Let’s change drawing method to “Bonds” and then type in the “Selected Atoms” box “resid 96 to 98 106 to 121”.
You should see the amino acids represented by sticks with the oxygen atoms colored red and the nitrogen atoms colored blue, this is a common coloring scheme. Uh oh. The crystal structure that we have is missing a part in the 106-121 region. You might ask how I know this by first glance and that is because proteins are like a strings, they should only have two ends. The beginning is termed the N terminus or the amino terminus because there is an unattached amino group that is usually used to form the peptide bond and protein chain. The ending is called the C terminus or carboxy terminus because it contains an unattached carboxylic acid. Sometimes loop regions are missing from X-ray structures because they are very flexible and can be in different conformations in the crystal. X-ray crystallography works because of a crystal’s repeating pattern so when the pattern is not repeated the data is not good. Many times in proteins these loop regions will be very interactive with other proteins or molecules because they stick away from the protein and that is also why they tend to be more flexible because they do not have other structures near them for “support”. Let’s see which residues are missing from the structure. On the Main window goto “Mouse” then “Label” and then choose “Atoms”. Now click on the amino acids that are on both sides of the missing loop.
You should see labels on LEU106 and GLU113. Do you remember what amino acids these are? It appears we are missing 6 amino acids and if we want to use this structure for simulations later we will need to have these amino acids in the structure so in the next section we will learn how to add them into the model! There are many other cool things that one can do with VMD. If you are interested in learning more check out this tutorial: http://www.ks.uiuc.edu/Training/Tutorials/vmd/tutorial-html/ .
Fixing Protein Structures and Generating Models
The current methods to solve the structural models of proteins are very time and skill intensive. Even with the many Structural Biology Consortiums we only have 10s of thousands of unique protein structures solved. Lots of research has gone into developing ways to use structures of related proteins to create models for proteins that do not have structures solved. This is called homology modelling and is a very useful technique when attempting to study protein structures computationally. My favorite tool to do this is SWISS-MODEL (http://www.swissmodel.expasy.org/interactive). Basically, all that you need is a protein sequence and it will attempt to generate a model for you. This can be done with any protein that has a slightly similar amino acid sequence to one of the structures already solved.
Here is the sequence of the VP24 Sudan Ebolavirus:
MAKATGRYNLVTPKRELEQGVVFSDLCNFLVTPTVQGWKVYWAGLEFDVNQKGITLLNRLKVNDFAPAWAMTRNLFPHLFKNQQSEVQTPIWALRVILAAGILDQLMDHSLIEPLSGALNLIADWLLTTSTNHFNMRTQRVKDQLSMRMLSLIRSNIINFINKLETLHVVNYKGLLSSVEIGTPSYAIIITRTNMGYLVEVQEPDKSAMDIRHPGPVKFSLLHESTLKPVATPKPSSITSLIMEFNSSLAI
Paste that into SWISS-MODEL “Target Sequence” and give the project a title “Sudan Ebolavirus” and hit “Build Model”!
You should end up with 3 models.
I choose the 3VNE.1A model. As this is a model based off the structure we were using before the only thing that should really be different is that we should have the missing loop now! So click on the “Model 01” button and then right-click on “PDB File” and choose “Save Link As”. Now let’s check our fresh model.
So let’s open up the model like we did before with VMD and change the Representation to “New Cartoon” so we can look at it easier. Now let’s see what our new loop looks like. Goto “Extensions” then “Analysis” and then at the bottom “Sequence Viewer”.
This should open up a window that shows the sequence. Now Let’s scroll to 106 to 113, the part of the structure that was missing before. To highlight all those residues at once drag and highlight.
Sweet! We now have a complete structure and we can begin doing some actual molecular dynamics simulations.